AI Begins to Pollute the Internet
An expert in cognitive science has been documenting the drek coming online from LLMs — and, hoo boy!
A recent post by Gary Marcus, an American psychologist and cognitive scientist, known most recently for his work related to artificial intelligence (AI), examined the tip of the ugly blue berg of sewage that has dropped from the LLM jet overhead into the already polluted waters of the Internet.
The examples he’s gathered from Twitter are eye-opening, and I’m sharing a few here because they are so emblematic.
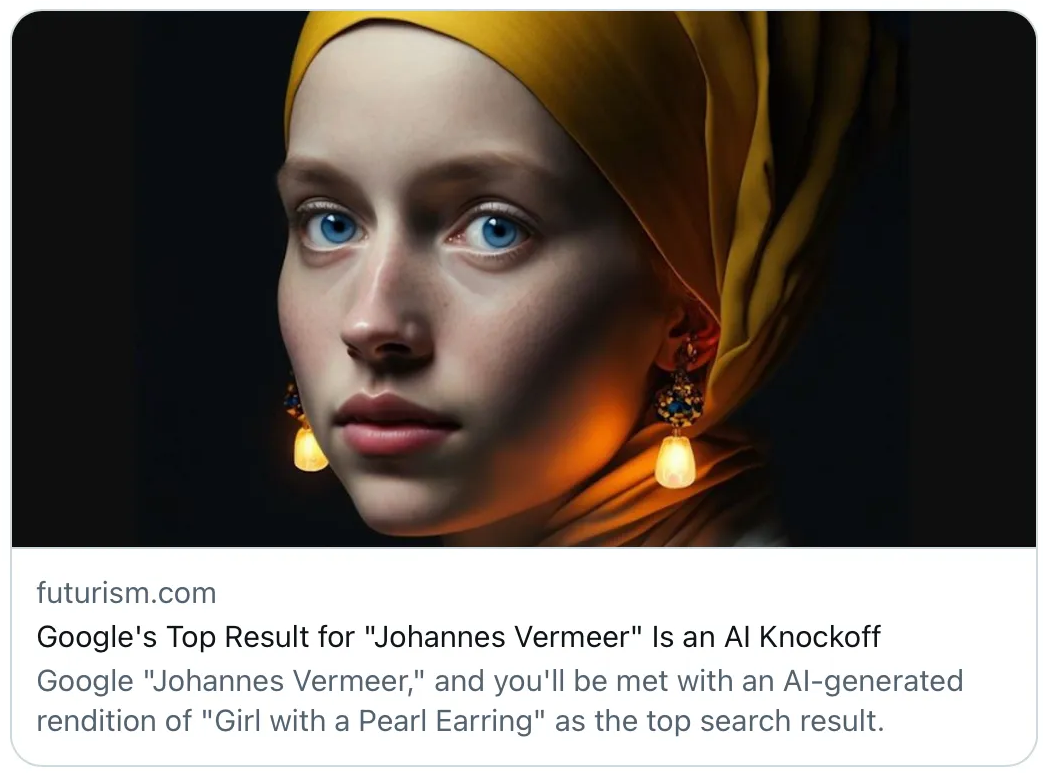
For example, classic works of artistic geniuses are being overwhelmed by AI knock-offs that mislead students, the lay public, and others as they infiltrate general search engines.
Other LLM nonsense shows that the model hasn’t learned to keep potentially poisonous combinations of household items off the menu:

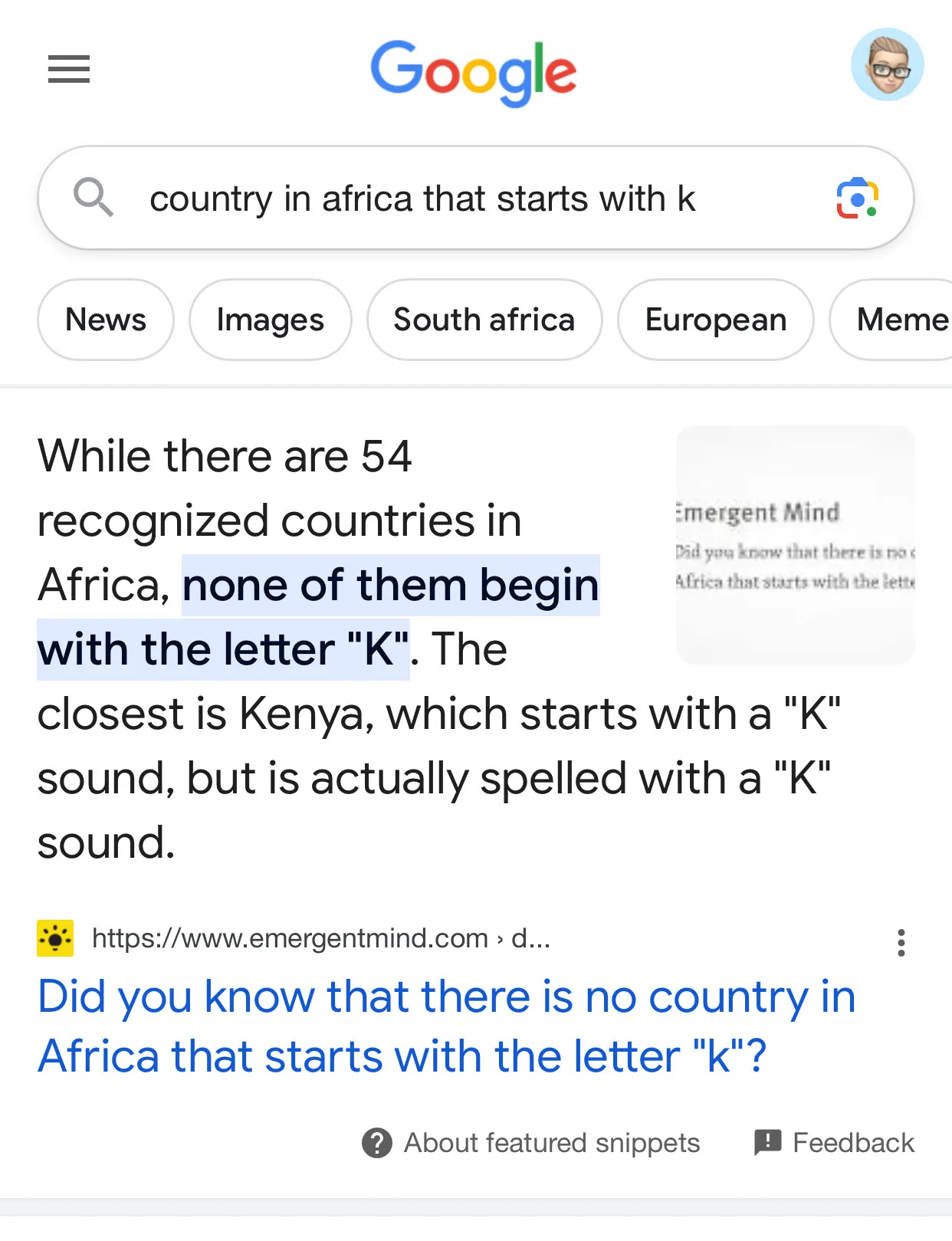
The drek being generated by LLMs is getting sucked into search engines, with Google falling for this doozy:
Meanwhile, Amazon is being swamped by low-quality and questionable travel guides and books about current events:

The challenges here are enormous, with major technology companies — Google, Amazon — already covered by unsavory LLM diaper blowouts. As Marcus writes:
Cesspools of automatically-generated fake websites, rather than ChatGPT search, may ultimately come to be the single biggest threat that Google ever faces. After all, if users are left sifting through sewers full of useless misinformation, the value of search would go to zero—potentially killing the company.
The site Newsguard tracks more than 400 unreliable LLM-generated news sites and the false narratives they have fostered. The list is growing fast — for both.
A new automatic LLM-drive misinformation system called CounterCloud has also been reported.
Of course, the threat to our own content stores is obvious. Yet, we continue to see a loosening of controls, a tolerance of unreviewed manuscripts via preprint servers, and an abdication of our role as arbiters of scientific and scholarly claims.
And while many journals quickly formulated policies against LLM-generated papers or text, I could find nothing on bioRxiv or medRxiv informing authors that LLM-generated papers or text is not acceptable.
If Google is wrestling with the pollution of its sophisticated, superbly engineered, and constantly refined and maintained search engine, what chance do more bespoke scholarly search engines have?
We should be uniting as a community to push for the regulation of LLMs and similar tools. As with any technology, how you use it matters, and volatile technologies like LLMs are especially concerning.