ORCID Wallpapers Over Its Flaws
Attempting to appear proactive, its response only highlights more shortcomings
Last week, I unexpectedly uncovered a set of entries in ORCID that seemed strange and worrisome — dozens of profiles for things like “darkweb bitcoin,” “order marijuana online,” and “amateur porn,” to name a few.
I suggested ORCID might want to “clean its room.” I also speculated that the laxity that appeared to be on display might fit with a larger theme around technology deployment, from social media to privacy to preprint servers:
How did this happen? I’m assuming that like so many other technology-driven products, ORCID failed to imagine how malefactors might abuse it, resulting in yet another mess that needs to be cleaned up.
After the post ran, I contacted Chris Shillum, the new-ish CEO of ORCID, to ask a few questions. He mentioned that he’d seen the post, but that ORCID was not inclined to respond. However, he did point me to ORCID’s “recently updated support article on the topic” of spammers.
In this support article, ORCID estimates that less than 2% of its accounts are “spam,” which would mean 200,000+ spam accounts off their current base of just over 10 million ORCIDs. It’s an estimate, not an analysis. Looking at their statistics, the estimate doesn’t line up with what you’d reasonably expect from a system filled with active, legitimate, scholarly accounts. Very few ORCIDs seem to be doing much heavy lifting for research and scholarship:
- Percent with person identifiers: 13%
- Percent with employment affiliations: 27%
- Percent with education and qualification affiliations: 27%
- Percent with membership and service affiliations: 3%
- Percent with funding activity: 3%
- Percent with peer review activities: 5%
- Percent with research resource activities: 0.01%
- Percent with works: 27%
The number 27% shows up the most. If this is an indicator of the actual level of scholarly use of ORCID, it would mean that there are fewer than 3 million legitimate, active records, leaving north of 7 million serving some other purpose.

The support article I was directed to also states (emphasis theirs):
We rely on the vigilance and goodwill of users to root out and alert us to fraudulent records via our dispute resolution process and invite you to continue this by reporting any problematic records you find to our Support Team.
In their “Dispute Procedures” document, ORCID writes:
ORCID does not edit or curate data; that is the responsibility of individual Record Holder and Members. While ORCID does not control the data in the ORCID Registry or individual records, it is committed to supporting a transparent and accurate data environment.
How you get accuracy without control is a worthwhile question. But the takeaway is that monitoring for fraudulent records is a job for users. This kind of abdication of responsibility for the data in a platform seems worse than Parler’s infamous “we have a tag-team jury” approach, and less responsible than any social media site currently. So, let’s call this inadequate.
The dispute resolution process is unlikely to work swiftly or well, requiring users to file disputes one-by-one via a form that is hard to locate — it’s not even linked to from the page. The form has four required fields, and doesn’t seem designed to purpose. The amount of legalese on the “Dispute Procedures” page lies somewhere between intimidating and impressive.
But it was Shillum’s use of the term “. . . recently updated . . .” to describe the support article about spammers that really caught my eye, as it conveyed the impression that ORCID had been publicly addressing the topic of spammers before my post. It also suggested that I’d missed this, which I’d have been embarrassed to learn.
He emphasized this further in a subsequent email, writing:
As alluded to in our support article, we’ve been aware of this issue for many years and have policies in place to manage it.
Shillum’s words turned out to be a shading of the truth. From what I can tell, the article hadn’t been “updated” as part of consistent public messaging to build awareness of spam accounts. It appears to be brand new, created in the wake of my post last week and published only hours before he emailed me.
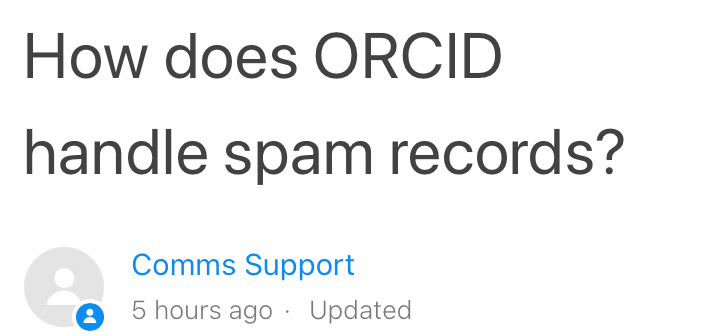
Here’s why I’m convinced this page was put up after my post on February 24, 2021. See if you agree.
Shillum responded to my email and sent the link to the support article on Friday, February 26. I read it around 7:30 p.m. ET, and followed the link he shared. At that time, the post stated it had been updated 5 hours ago, as shown below:
The page also employed language reminiscent of the findings in my post from February 24, 2021, just two days prior:

According to the Wayback Machine, this page did not exist when the site was last crawled in late-November 2020. I asked Shillum when the page was created, and he declined to answer.
However, I think we can discern the answer without him by reviewing the source of the page, where some reliable metadata seems to exist (screenshot from four hours later, with the relevant page source placed below):

To check the reliability of my assumption about the metadata, I looked at two other pages in ORCID’s support system. One page, created four months ago, had metadata showing it had been created exactly four months prior — October 26, 2020.

Another page marked as having been created two years ago also seems to validate this metadata as an accurate representation of when pages are created, given that the year count probably doesn’t increment until September 25, 2021:

I went from worrying I’d missed something to feeling like I was being gaslighted.
Other questions Shillum declined to answer:
- Why is controlling entries to ORCID such a challenging issue?
- What proactive steps are you going to take now that you’re aware of these issues?
- Have you had any disputes filed through your dispute resolution process? How many? How were they resolved? Who makes the decisions?
Shillum could have easily said, “Yes, we saw the story and created the following page in response. I’d be happy to answer any further questions,” and then answered them. I think my questions were fair, and his answers could have shed some light and created some sympathy for whatever ORCID is dealing with. It seems like a real headache.
Some of the problems stem from GIGO-inducing policies. Why not check and validate each and every entry — providing users with an SLA of 48-72 business hours for a decision on a filing request?
As it is, in addition to the problematic terms I flagged last week, fictional characters like Hannibal Lecter, Tony Stark, Princess Leia, and Clark Kent all have identifiers in a system.
ORCID’s process for detecting and removing bogus records isn’t adequate. Nor was their initial response to reporting on the problem. There are better-managed researcher identification systems out there, too. It’s not like ORCID has cornered the market.
ORCID seems to be missing a big opportunity here — to create an identifier users could wield with pride and confidence; to create an open system users can trust; and, to quash abuse of author identities. But something is keeping them from embracing these rich and important possibilities.
No matter what, wallpaper and gaslights aren’t a good look for ORCID.