Can You Retract from an LLM?
Atomized, tokenized, and weighted, papers may not be addressable anymore
Our recent podcast discussion of the “double bubble” faced by scientific publishers — OA and AI — caused me to finally try to address a question that’s been on my mind off and on:
- Can a paper be retracted from an LLM?
Let’s look at two LLMs in medical publishing used by two top medical journals — NEJM’s “AI Companion” and OpenEvidence (which adds JAMA, among others) — to gauge an answer.
Bottom line? Expect the unexpected.
Let’s dive in.
NEJM’s AI Companion
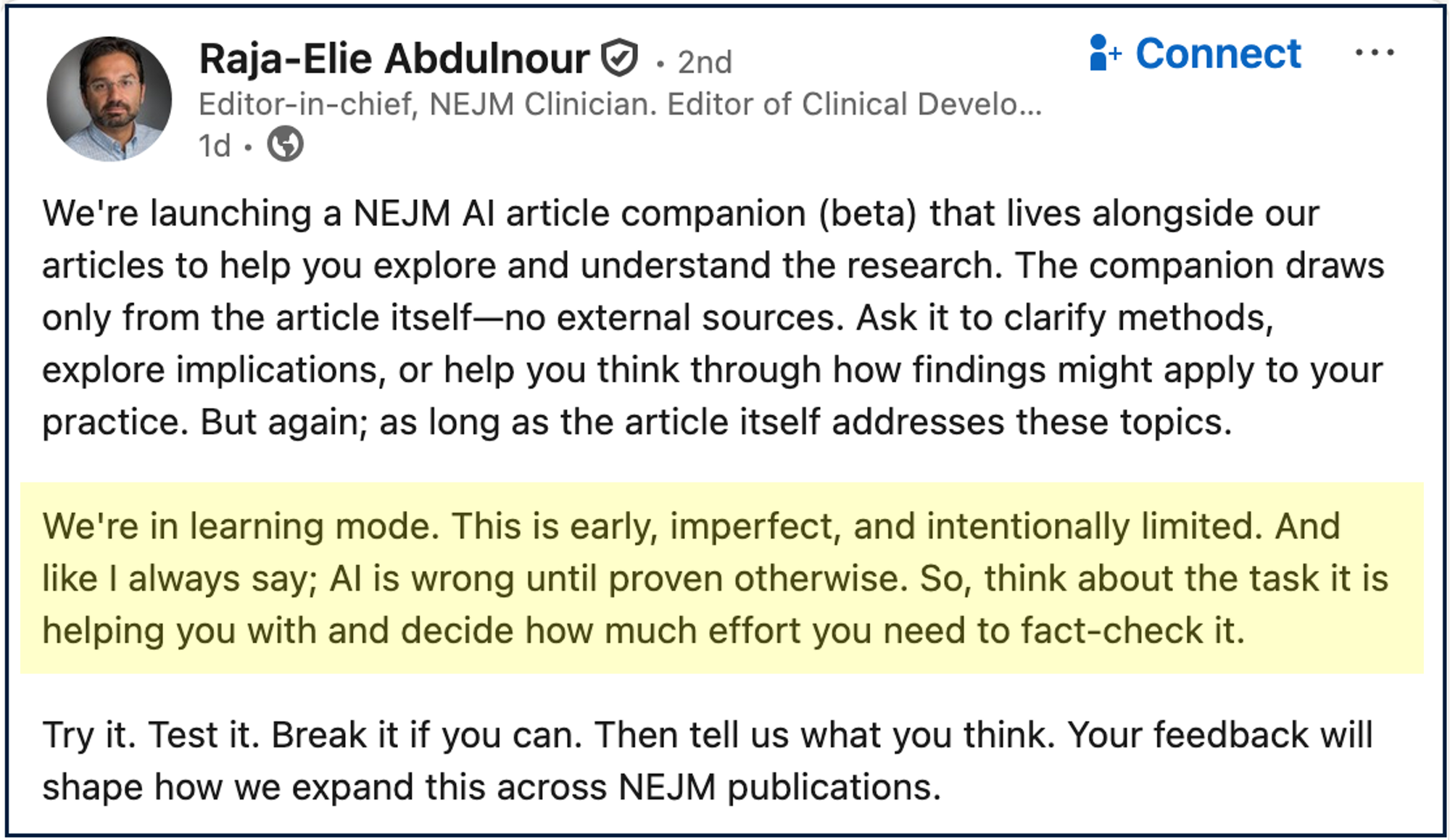
NEJM’s recently launched AI Companion didn’t start auspiciously. Even those responsible for it admitted it was half-baked and likely to fail (highlight mine) as they externalized risk to users:
Instead of making it tell me lies or write letters to Santa or Harry Potter as before, today let’s examine how the AI Companion deals with a retracted article.
As you might recall, this is an article-level system designed to . . . do stuff at the article level. (I really can’t cheerlead since I can’t conjure any solid reason for it to exist.) But whatever it does, you’d expect it to shine at the article level.
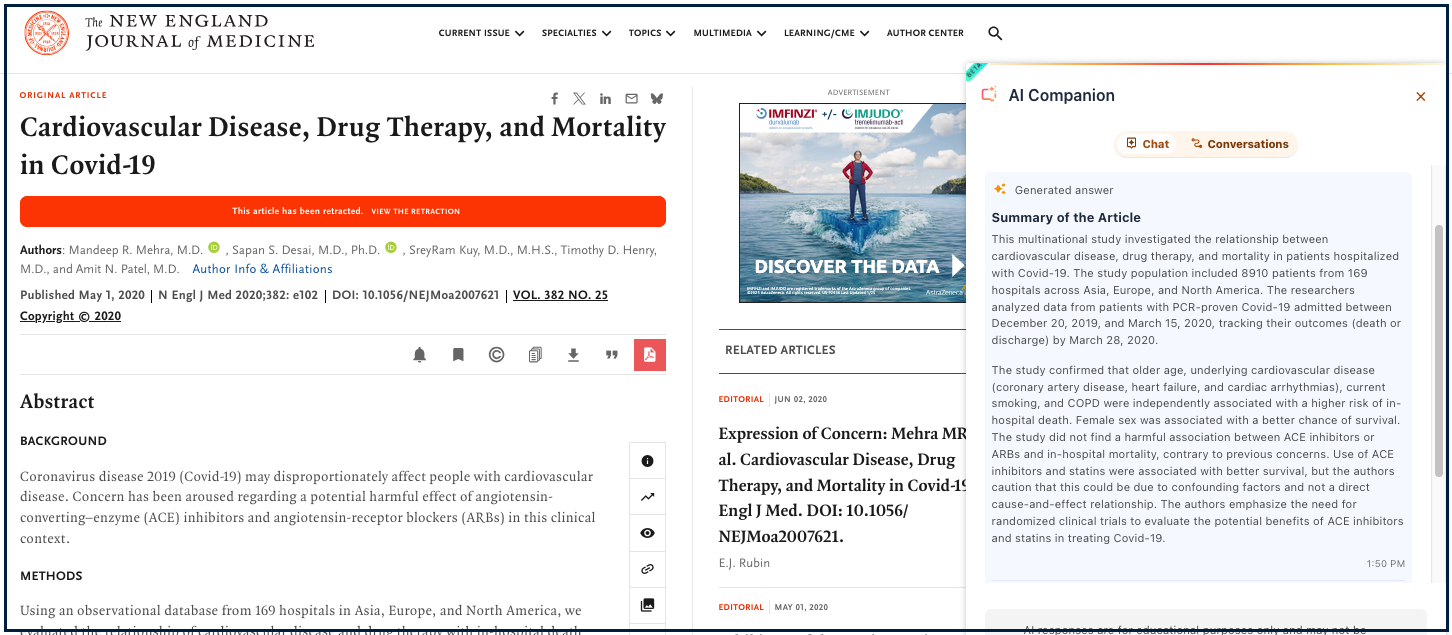
In May 2020, a research article about cardiovascular disease, drugs, and mortality around Covid-19 was published in NEJM. It was retracted weeks later (June 2020) by the authors because not all authors had access to the underlying data. They apologized.
Running NEJM’s AI Companion on the retracted article, I was anticipating the system would have some wording about how the article’s claims could not be relied upon due to its status as a retracted article, or some such stuff. Instead, this is what I received:

Pretty confident for a retracted study.
To show you how proximal to the retraction notice this was, here is the page with the AI summary on the right and the red retraction notice on the left:
The red bar is the retraction notice and link:

Yet, even with all this information available — a prominent link to a retraction explaining when and why this paper was retracted — the NEJM AI Companion was totally at sea when asked about it:
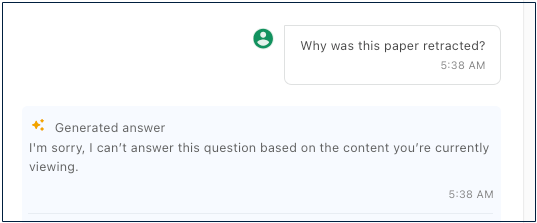
Notice that a human with a modicum of experience with scientific journals would have no trouble assessing the situation — here is a paper that has been retracted, a link to an explanation, and an abstract summarizing the now-retracted findings. Yet, if I use the NEJM AI Companion, this article-level system is ignorant of a status I can see with my own eyes. The LLM can‘t see a retracted article.
Verdict: Fail.
- Did I mention that I really can’t find any epistemic or scientific reason for the NEJM AI Companion to exist?
To write the remainder of this post, I asked a few experts in cognitive science, neural nets, and LLMs for their thoughts. I hope I am representing their insights well enough.
OpenEvidence and Retractions
For these next examples, let’s look at OpenEvidence, an LLM that has secured content deals with NEJM, JAMA, and a handful of other top medical journals. I covered some fundamental problems with OpenEvidence recently, and others have noted similar issues, with one critic writing:
[I]s OpenEvidence reliable and trustworthy? The answer is: sometimes.
For retracted articles, the norm in scientific and scholarly publishing is that a work is retained and marked accordingly, thereby preserving a record with the additional information that the work proved problematic. According to COPE:
Notices of retraction should link to the retracted article, clearly identify it with title and authors, and be published promptly and be freely accessible to all readers.
Yet, this form/norm of retraction doesn’t seem possible if the paper is integrated into an LLM.
- Does that place LLMs out of compliance with COPE?
- A question for another day . . .
However, retractions seem to confuse LLMs, while LLMs flummox those applying them. This latter point may be the most worrisome, as the publishers of NEJM and JAMA both seem unwilling or unable to explain exactly how the LLMs they’ve contracted with work. Even OpenEvidence seems unwilling/unable.
I finally got an answer from a spokesperson at NEJM. And it was puzzling:
OpenEvidence expunges retracted articles from their system.
“Expunge” is a complicated concept for an LLM, as it means to erase or remove completely. As I understand it, LLMs process content by atomizing and tokenizing it. The system then generates weightings, which interact with these individual tokenized content elements across a neural net architecture. Weightings evolve over time as statistical relationships are modified by usage patterns and neural net pathways are carved into deeper statistical ruts. Things can change when new content tokens appear or users ask new questions. It’s all quite dynamic, with each original item uploaded becoming less addressable over time due to that dynamism and the fragmented nature of the content and weightings in a neural net architecture.